Rows: 7,431
Columns: 8
$ id <dbl> 0, 1, 10, 100, 1000, 1001, 1002, 1003, 1004, 1005, 1006, 1…
$ title <chr> "\"H\" IS FOR HOMICIDE", "\"I\" IS FOR INNOCENT", "''G'' I…
$ author <chr> "Sue Grafton", "Sue Grafton", "Sue Grafton", "W. Bruce Cam…
$ year <dbl> 1991, 1992, 1990, 2012, 2006, 2016, 1985, 1994, 2002, 1999…
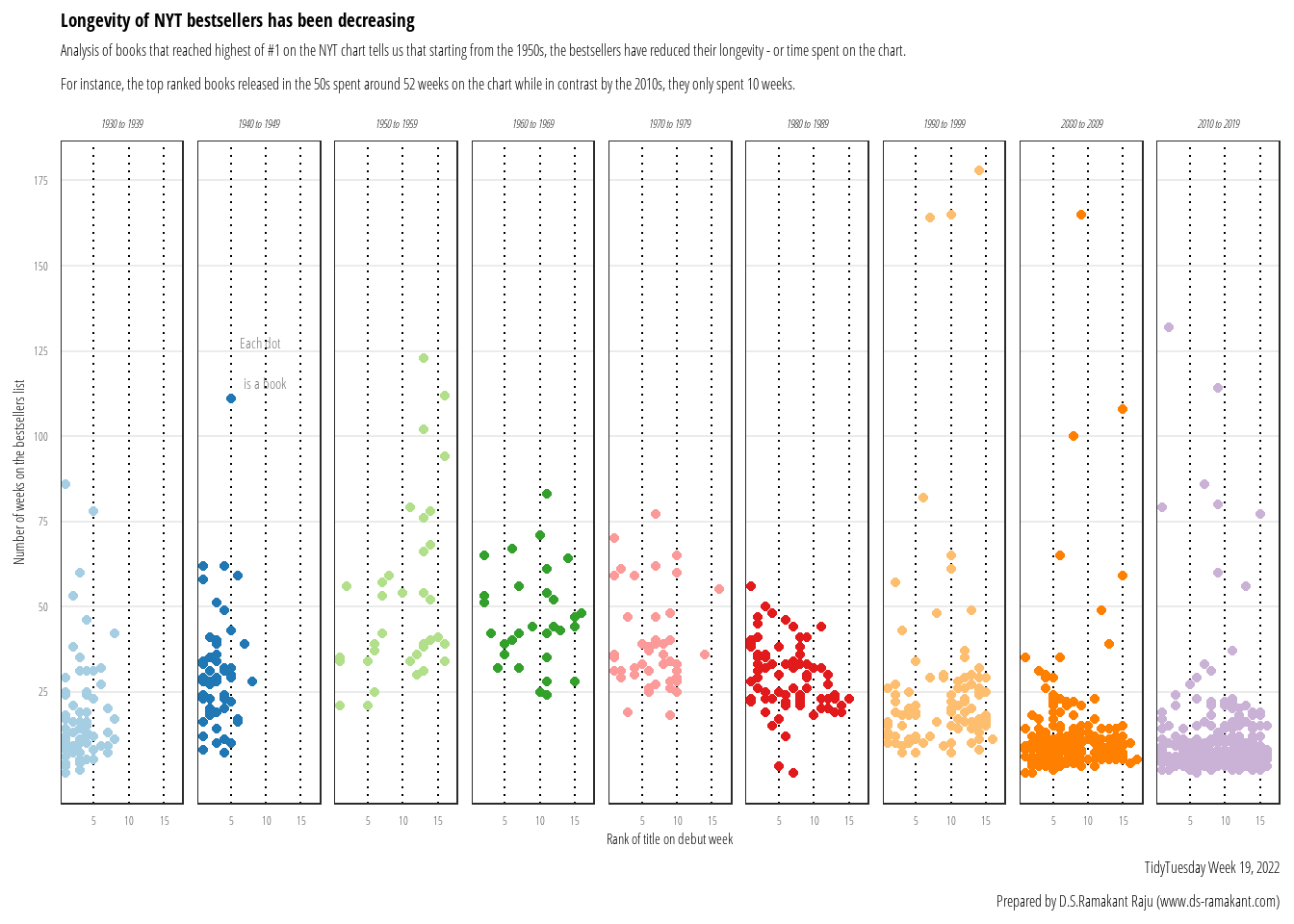
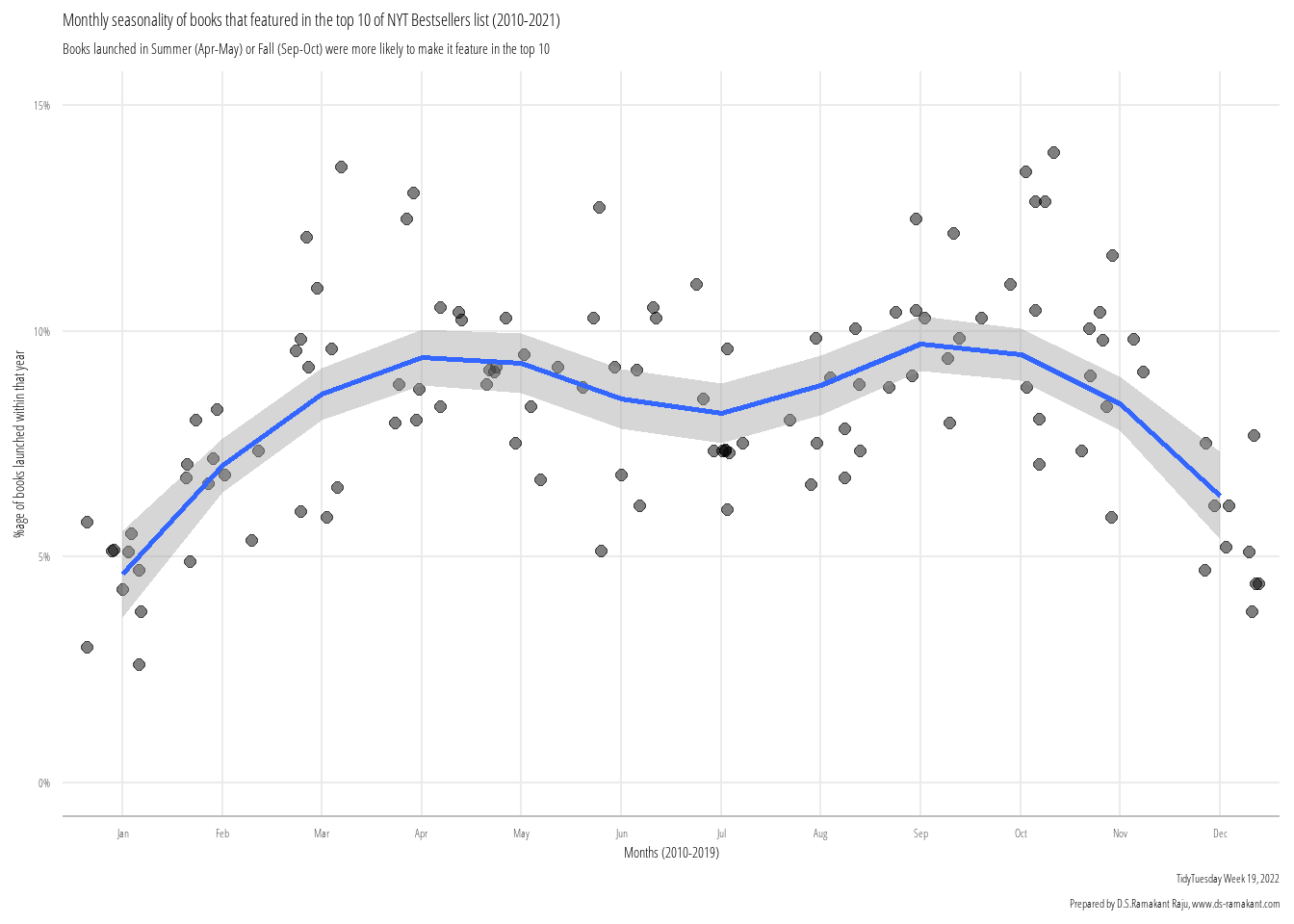
$ total_weeks <dbl> 15, 11, 6, 1, 1, 3, 16, 5, 4, 1, 3, 2, 11, 6, 9, 8, 1, 1, …
$ first_week <date> 1991-05-05, 1992-04-26, 1990-05-06, 2012-05-27, 2006-02-1…
$ debut_rank <dbl> 1, 14, 4, 3, 11, 1, 9, 7, 7, 12, 13, 5, 12, 2, 11, 13, 2, …
$ best_rank <dbl> 2, 2, 8, 14, 14, 7, 2, 10, 12, 17, 13, 13, 8, 5, 5, 11, 4,…